
Exploring the Technical Innovations of DeepSeek V3
DeepSeek V3 has emerged as a formidable player in the realm of open-source AI models, showcasing an impressive blend of innovation and efficiency. With a staggering 671 billion parameters, yet only 37 billion activated per token, this model is designed to optimize performance while minimizing resource consumption. In this blog, we will delve into the key technical innovations that set DeepSeek V3 apart from its competitors.
Key Technical Features
Mixture-of-Experts (MoE) Architecture
At the heart of DeepSeek V3 lies its Mixture-of-Experts (MoE) architecture. This sophisticated design allows the model to utilize multiple smaller, task-specific networks that work collaboratively. When a query is received, a gating network determines which expert models to activate, ensuring that only the necessary components are engaged for each task. This selective activation significantly enhances efficiency and performance.
Multi-head Latent Attention (MLA)
DeepSeek V3 employs Multi-head Latent Attention (MLA) to improve context understanding and information extraction. This approach not only maintains high performance but also reduces memory usage during inference through low-rank compression techniques. As a result, DeepSeek V3 can efficiently process complex queries while retaining accuracy.
Auxiliary-Loss-Free Load Balancing
One of the standout innovations in DeepSeek V3 is its auxiliary-loss-free load balancing strategy. Traditional load balancing methods can adversely affect model performance; however, this novel approach minimizes such impacts, leading to more stable and efficient training processes.
Multi-token Prediction Objective
DeepSeek V3 introduces a multi-token prediction training objective, which enhances its ability to generate coherent and contextually relevant text. This feature allows the model to predict several tokens simultaneously, thereby improving its generation speed and overall efficiency.
Performance Metrics
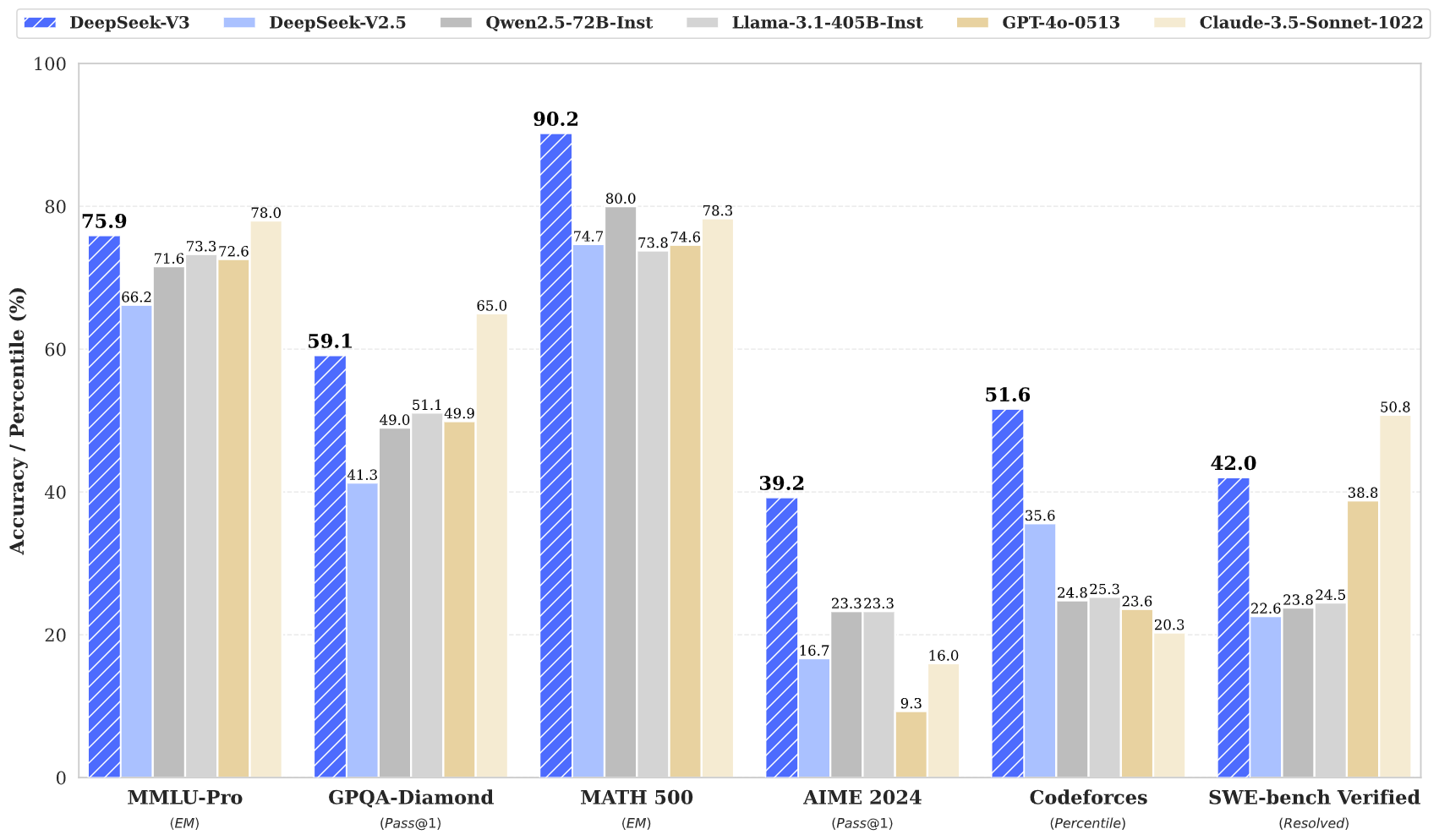
DeepSeek V3 has demonstrated exceptional performance across various benchmarks:
- MMLU: 87.1%
- BBH: 87.5%
- DROP: 89.0%
- HumanEval: 65.2%
- MBPP: 75.4%
- GSM8K: 89.3%
These metrics indicate that DeepSeek V3 not only competes with but often surpasses leading closed-source models like GPT-4 and Claude 3.5, particularly in complex reasoning tasks and coding challenges.
Training Efficiency
The training of DeepSeek V3 was achieved with remarkable efficiency:
- Total Training Cost: Approximately $5.6 million
- Training Duration: 57 days
- GPU Hours Required: Only 2.788 million H800 GPU hours
This cost-effective training approach highlights how innovative architecture can lead to significant savings compared to traditional models, which often require substantially higher resources.
Context Window and Speed
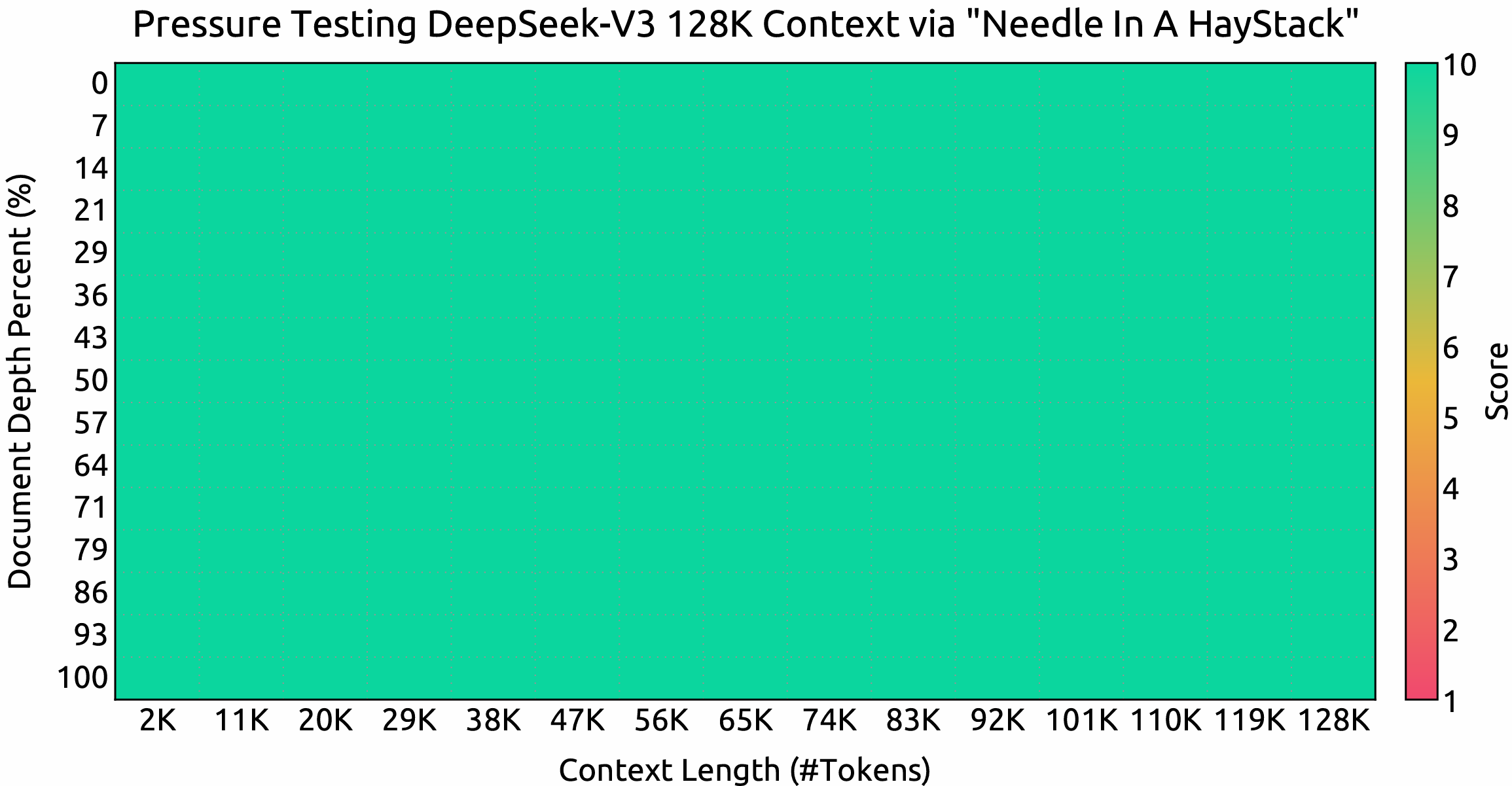
DeepSeek V3 supports an impressive 128,000-token context window, allowing it to handle long-form content and complex tasks effectively. Additionally, it boasts a generation speed of up to 90 tokens per second, making it one of the fastest models available today.
Final Wording
In summary, DeepSeek V3 stands out as a revolutionary advancement in open-source AI technology. Its innovative architectures—MoE and MLA—combined with efficient training strategies and impressive performance metrics make it a strong contender in the competitive landscape of AI models. As the demand for powerful and accessible AI solutions continues to grow, DeepSeek V3 is well-positioned to lead the charge towards democratizing AI technology.